
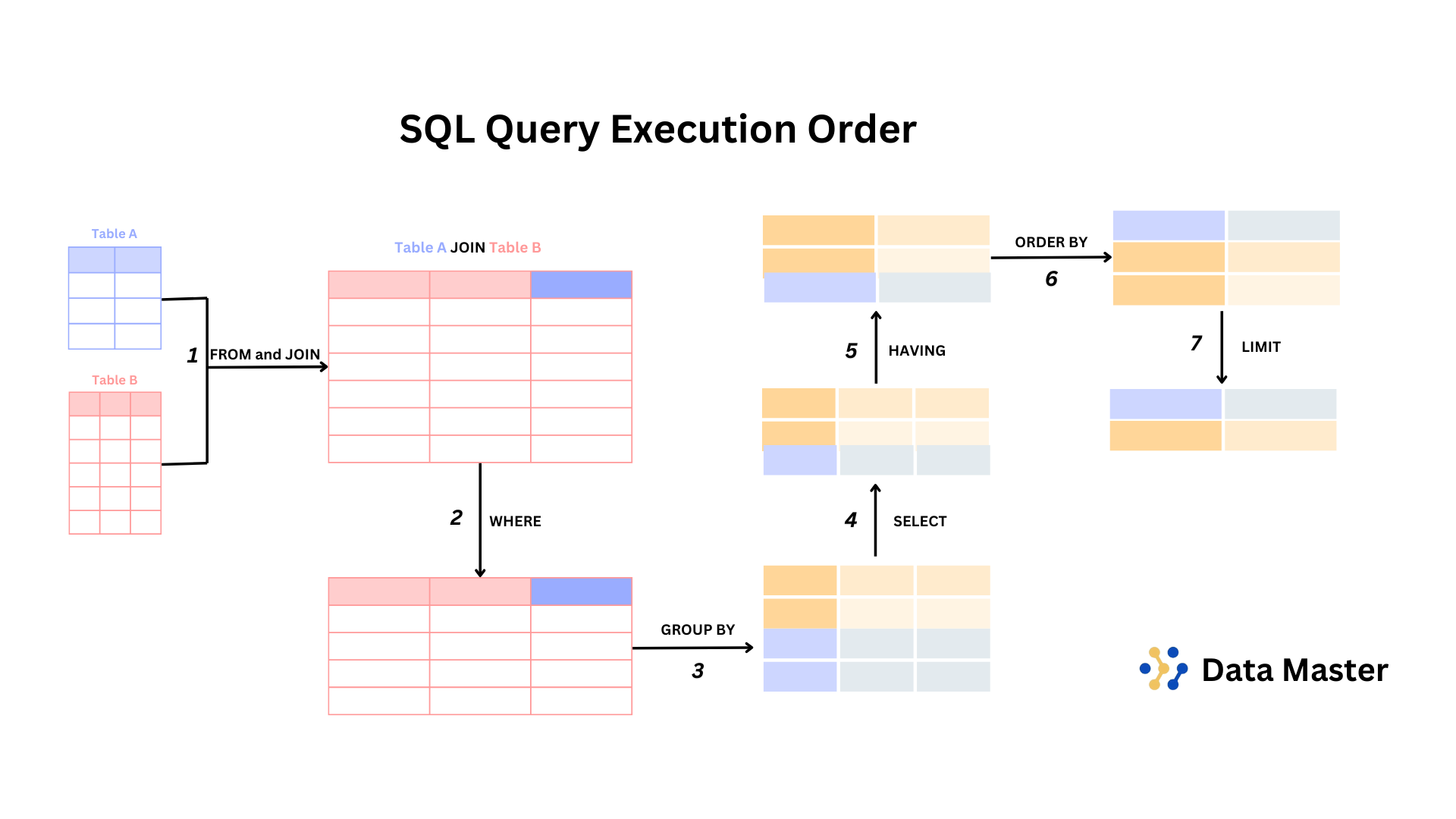
When writing SQL queries, the logical order in which SQL clauses are executed might differ from the way we typically write them. The diagram above gives us a visual understanding of how a SQL query is processed. Let’s break it down step by step, following the flow from source data to the final output.

1. Source: FROM & JOIN
The process begins with identifying the source tables from which the data will be fetched. In most cases, multiple tables are involved, so SQL starts by retrieving the data through the FROM clause, and if there’s a need to combine data from more than one table, JOIN operations are performed.
- FROM: Selects the table(s) to query.
- JOIN: Combines rows from different tables based on a related column (usually a foreign key).
At this stage, you end up with a merged dataset that contains all the columns and rows from the joined tables.
2. Filter: WHERE
Once the data is merged, the next step is to filter it. This is where the WHERE clause comes into play. SQL applies the WHERE conditions to reduce the data to only those rows that meet the specified conditions. This is critical for narrowing down the results as early as possible, which enhances query performance.
- WHERE: Filters rows based on conditions like age > 30, status = ‘active’, etc.
At the end of this phase, the result is a filtered set of data that only contains the rows that satisfy the WHERE clause conditions.
3. Grouping: GROUP BY
Once we have a filtered dataset, we may want to group the data to aggregate it. This is done using the GROUP BY clause. It groups rows that share the same values in specified columns and allows you to perform aggregate operations like SUM(), COUNT(), AVG(), etc., on each group.
- GROUP BY: Groups rows based on the unique values of one or more columns, allowing for aggregation.
The output of this step is a grouped dataset, where each group represents a unique combination of values from the specified columns.
4. Group Filtering: HAVING
After the data is grouped, we might want to filter out some groups based on the result of aggregate functions. This is where the HAVING clause comes into play. Unlike the WHERE clause, which filters individual rows, HAVING filters groups.
- HAVING: Filters groups based on aggregate conditions like SUM(sales) > 1000.
At this point, we have a filtered set of grouped data, ready for further processing.
5. Selection: SELECT
After filtering and grouping, SQL decides what columns to display in the final output. The SELECT clause specifies which columns (or aggregate functions) should be included in the result.
- SELECT: Chooses which columns or expressions will appear in the final result.
Once selected, the result is a selected set of data, formatted based on the required columns or expressions.
6. Ordering: ORDER BY
Next, we often want to order the final result. The ORDER BY clause is used to sort the result set based on one or more columns. This helps in arranging the data in a meaningful way, whether it’s ascending or descending.
- ORDER BY: Sorts the result set based on specified column(s).
After this step, we have an ordered dataset that is sorted according to the specified criteria.
7. Limiting: LIMIT & OFFSET
Finally, to control the amount of data returned, SQL uses the LIMIT and OFFSET clauses. LIMIT specifies the maximum number of rows to return, while OFFSET allows skipping a specified number of rows.
- LIMIT: Restricts the number of rows in the result.
- OFFSET: Skips a certain number of rows from the start.
At the end of this stage, you have a limited and final result set that contains only the rows you want to display.
Conclusion
Understanding the flow of SQL execution helps in writing efficient queries and optimizing performance. The key takeaway is that while SQL queries are written in a specific order (SELECT, FROM, WHERE, GROUP BY, etc.), they are executed in a different logical order. By mastering this flow, you can better understand how your query operates behind the scenes, allowing for improved query design and performance tuning.
Discover more from Data Master
Subscribe to get the latest posts sent to your email.