
In today’s data-driven business environment, organizations rely on robust data storage and processing to make informed decisions. Data warehousing is a crucial part of this process, enabling businesses to consolidate and analyze data from multiple sources. At the heart of effective data warehousing is dimensional modeling—a design technique that structures data to facilitate easy access, efficient reporting, and insightful analysis.
This blog post will introduce the foundational concepts of dimensional modeling, explain why it’s essential for data warehousing, and explore its main components: fact tables and dimension tables.

What Is Dimensional Modeling?
Dimensional modeling is a data design methodology tailored specifically for data warehouses. Developed by Ralph Kimball, one of the pioneers in data warehousing, this approach structures data to support easy querying and high-performance analytics.
In a dimensional model, data is organized into two primary types of tables: fact tables and dimension tables. This arrangement helps users intuitively navigate and understand the data. The simplicity and efficiency of dimensional modeling make it ideal for handling large datasets and generating business insights.
The Importance of Dimensional Modeling in Data Warehousing
Unlike operational databases, which are optimized for transactional processing, data warehouses are optimized for analytical processing. Dimensional modeling offers several advantages in this context:
- Simplicity: Dimensional models are easy to understand and use, even for non-technical users.
- Performance: By organizing data in a structure that reduces the number of joins in queries, dimensional models provide faster query response times.
- Flexibility: Dimensional models are highly adaptable and can easily support changes, such as the addition of new dimensions or facts.
- Enhanced Reporting: The structure of a dimensional model supports efficient data retrieval, making it easier to generate insightful reports.
Key Components of Dimensional Modeling
Dimensional modeling is built around two core components: fact tables and dimension tables. Let’s take a closer look at each.
- Fact Tables
A fact table contains the quantitative data or metrics of a business process. Each row in a fact table represents a measurement or transaction, such as a sale or customer order. These measurements are often numeric and additive, meaning they can be summed up across dimensions.
For example, in a sales database, the fact table might include metrics such as “sales amount” or “quantity sold.” Each fact table row is also associated with foreign keys that link to the corresponding dimension tables, adding context to each metric.
Fact tables come in different types based on the nature of the metrics they store:
- Additive facts: Can be summed up across all dimensions (e.g., total sales).
- Semi-additive facts: Can only be summed up across some dimensions (e.g., inventory levels).
- Non-additive facts: Cannot be summed up at all (e.g., unit price).
- Dimension Tables
Dimension tables provide descriptive information that gives context to the measurements in the fact tables. They answer questions like who, what, where, when, and how about each measurement. Dimension tables are usually textual and include attributes that categorize and organize data.
For example, a dimension table for product information might include columns for “Product Name,” “Category,” “Brand,” and “Size.” Similarly, a “Time” dimension could have attributes like “Month,” “Quarter,” and “Year,” helping users filter and analyze data by specific periods.
Dimension tables often have hierarchical relationships, such as Country > State > City or Year > Quarter > Month. These hierarchies make it easy to “drill down” into more detailed data or “roll up” to a summary view.
Star Schema: The Foundation of Dimensional Modeling
In dimensional modeling, data is often organized in a star schema. In this structure, the fact table is at the center, surrounded by dimension tables. The star schema gets its name from this layout, as the arrangement resembles a star with the fact table at the center and dimension tables radiating outward.
The star schema is popular for several reasons:
- Simplicity: It’s easy to understand and straightforward to query.
- Efficiency: With fewer joins compared to traditional relational database models, the star schema enables faster querying.
- Extensibility: New facts and dimensions can be added with minimal disruption to the existing schema.
An alternative to the star schema is the snowflake schema, where dimension tables are further normalized into related tables. However, star schemas are generally preferred in data warehousing due to their simplicity and performance benefits.
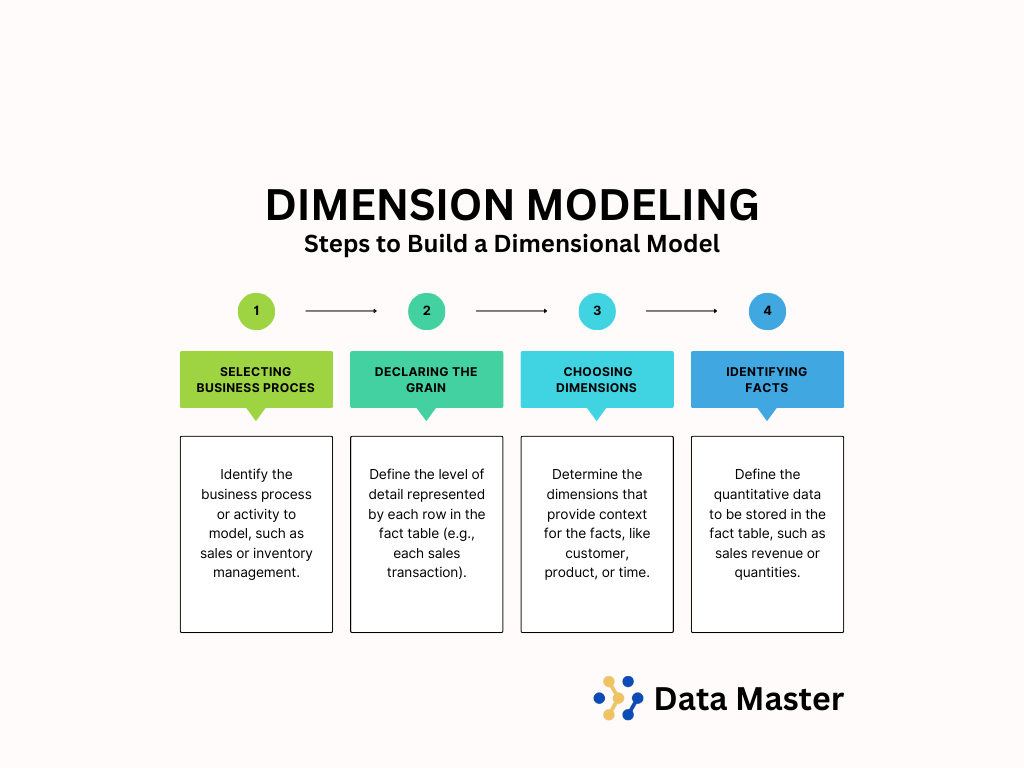
Steps to Building a Dimensional Model
Building a dimensional model typically involves the following steps:
- Select the Business Process: Identify the business process or activity to model, such as sales or inventory management.
- Declare the Grain: Define the level of detail represented by each row in the fact table (e.g., each sales transaction).
- Choose the Dimensions: Determine the dimensions that provide context for the facts, like customer, product, or time.
- Identify the Facts: Define the quantitative data to be stored in the fact table, such as sales revenue or quantities.
Following these steps ensures that the dimensional model is both relevant to business needs and efficient for analytical purposes.

Conclusion
Dimensional modeling is a powerful technique that enables organizations to leverage their data for valuable insights. By organizing data into easily understood fact and dimension tables, dimensional modeling supports fast, flexible, and accurate reporting and analytics. As more businesses turn to data-driven decision-making, understanding and implementing effective dimensional models is becoming an essential skill for data professionals.
Whether you’re new to data warehousing or looking to refine your data modeling approach, mastering the basics of dimensional modeling can help you build data warehouses that are not only efficient but also a powerful source of business insights.
Dimensional modeling forms the backbone of a high-performing data warehouse. With its simplicity, efficiency, and scalability, it’s no wonder this approach has become the gold standard for structuring data for analytics. Ready to dive deeper? Keep following our blog series to learn more about advanced concepts and best practices in data warehousing.
Discover more from Data Master
Subscribe to get the latest posts sent to your email.